Devlog Entries
Devlogs are small frequent updates as I complete tasks across various projects.
Olympics event
Today I added Olympics events to AeroCEO.
Olympics events occur every four years at scheduled host cities. The host airport and its region receive a temporary tourism boost, which increases passenger demand on routes serving those locations. Following the event, the host airport receives a permanent increase to its base tourism rating, to account for the improvements the city made.
I'll probably have to change the name in the final release, as Olympics is probably a protected thing. So maybe "Copyrighted sports event" or "Quadrennial sporting event".
Ventures
I've been working on buying and selling business ventures in AeroCEO. Ventures give bonuses to city stats which can help you ship more passengers and make more money.
Ventures are predefined for each airport, and smaller ones have less options. Also only one company can own a venture so first in best dressed!
I've added veeeeeery simple buy and sell buttons to the airport GUI.
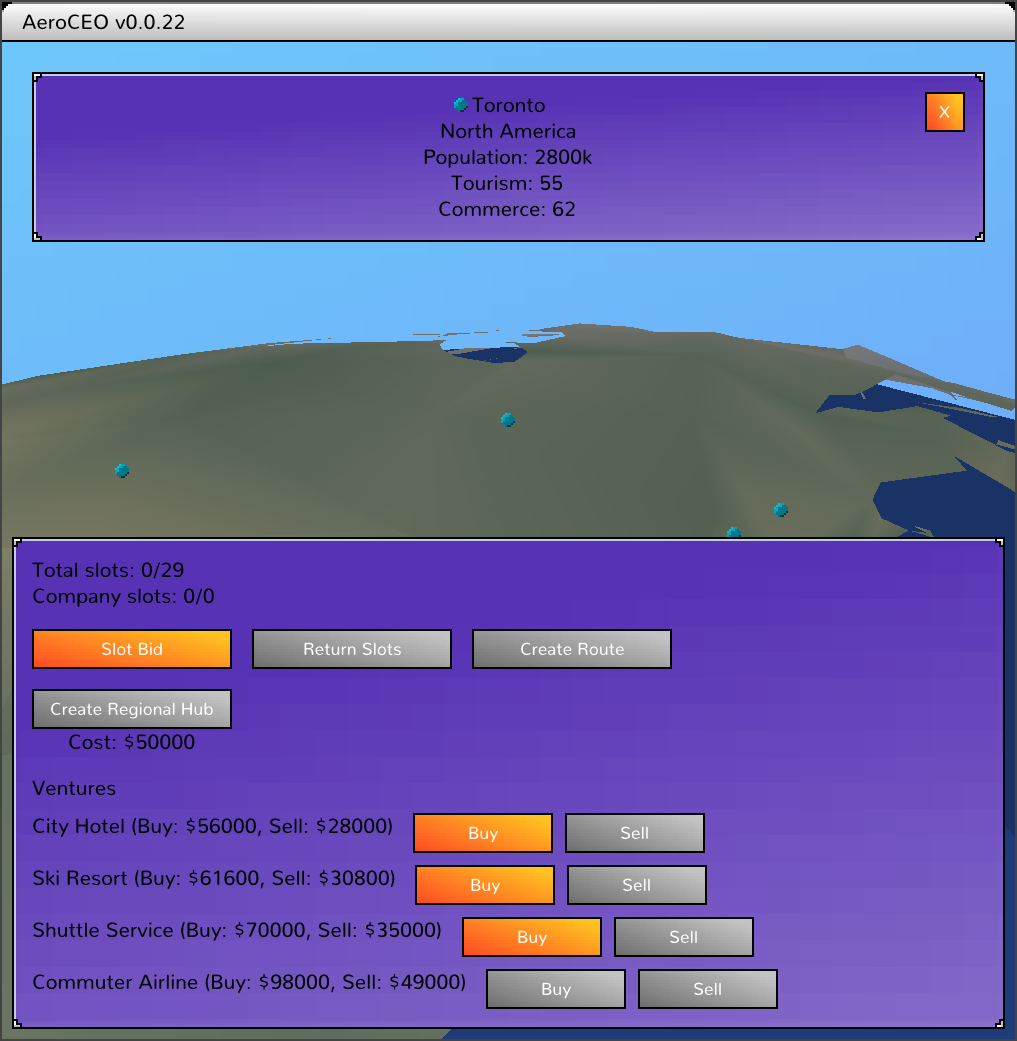
Purchasing takes an agent and a turn, so it's possible that two companies can try to purchase at once. In that case one will get refunded at the end of the turn.
Selling also takes an agent and a turn, but you don't get as much money back, so choose wisely!
Setup automated UI testing
I've setup a first pass of automated UI testing in AeroCEO.
Earlier, I had already separated the GUI code into it's own library, this way I could have it loaded into a normal executable for releasing the game. But also in an second executable along with the server code for easily development and testing without having to run a server separately. Now I can load this GUI within a third executable, within a testing framework that can push buttons and speed through time to allow for writing tests.
I've just got a simple proof of concept for now, where the game will wait until the splash screen disappears and the main menu is available, then clicks the start game button, then confirms that it is now in the game proper.
In the future we'll be able to do lots of tests to check every screen and menu to make sure the game is solid and bug free as I improve and extend it.
UI Dock
I've start work again on improving the UI for AeroCEO. I've created a top level dock to access the main functionality the player needs. Can you tell that it's programmer art?

I've also started creating more screens for viewing all your airplanes and airports.
Remote join room
Now that authentication and user to process linking is coming along, we can now have rooms created on different servers and seamlessly join clients to them.
This is good as when we scale up servers, players can be located on any random one. So if they were wanting to play together we need to be able to get them in the same room on the same server.
This will also allow us to seamlessly shut down servers in the future, when scaling down or when restarting to apply updates. Usually a player will stay on the same server when changing rooms, but if that server is due to shut down, we can take that opportunity to send them elsewhere. This will slowly empty the server until it's safe to shutdown.
When changing rooms, if it's on the same process, we can just move the user across, and send down the new data. And if it's on a different server, we can now send back a message to the client telling them which server to connect to with a redirect auth token. The token is processed on the new server, and the user is moved to the room, and the client is finally sent the data.
Real cryptographic rand
When redirecting we randomly generate a token for the client to use to validate on the next server. Previously this was using our existing Rand functionality that uses PCG32. While that generator is very cool and fast for games, it's not really cryptographically secure. So we want to use something better for things like tokens and password hashing.
This is pretty easy to implement, we can just wrap the system cryptographic random functions to make them available in our custom language NLL. In C++ on linux we use getrandom and in C#, System.Security.Cryptography.RandomNumberGenerator.
Currently we just generate Uint32 and Uint64 on demand, we'll probably need to extend that in the future, but it's good enough for now.
Redirect improvements
Currently when being redirected to a new server, the client just replays the last thing that was sent to the previous server to authenticate. If that was an email/password then it works fine, but if it was a single use token or 2FA challenge then it would fail.
Since the user is authenticated before we decide to redirect them, we can create a special token they can use to authenticate on the new server. That way we don't have to worry about how they authenticated previously. We can also lock it down a bit by making the token single use and time limited.
It's pretty straightforward in the end, on the first server we create a random token, and insert it into the database with the userId. We send that token back to the client, and they submit it to the new server. On the new server we can then check for the token in the database to validate it, and see what userId is authenticating.
Server rejoin / redirect
I'm in the middle of some big changes around how auth and protocols and room joining. They are all complex and interleaved so they will mostly all be finished at the same time.
One smaller part of it tho is for players to be able to reconnect to their old game session. This is for things like if the game crashes, or if the user has connection problems. It can also allow for neat tricks like switching from mobile to PC.
So when a user reconnects to a server, we can detect if they have an existing game session and send them direct to that room, killing off the old connection in the process. The room can then send the current state to the newly joined connection and the player is back and ready to play.
If the player connects to a different server, we can also detect that and redirect them to the right place. This will be important as games scale up and run on many servers.
Remote Create Room
The basic architectural design of GameStrut is that there are servers and they have rooms. These rooms try to contain a segment of the overall gameplay.
For example in a gacha style game, one room might be for the home screen so it handles inventory and character management, another might be the shop that handles transactions and another might handle the battles. So as the player is moving through the game, behind the scenes on the server, different rooms are being created for them to transfer to to continue playing. When the player starts a battle, a battle room is created with the required parameters and the client seamlessly transitions to it.
Currently these rooms are all on the same server, but once we can make rooms on other servers, we can do lots more cool stuff. Like load balancing, or gracefully moving all the players off a server so we can apply updates or turn it off entirely. And at some point we will want players who are on different servers to be able to play together, so we need a way to send users to a room on a different server.
The first step to all of this is being able to do room creation via the database. Previously we'd just new a new room of the type we want, and move the user direct to it.
Now to start creating a room, we insert a row in the Room table, with a bundle of data needed to create the room, and we return the roomId. Now when creating the room, we can fetch the data fro the database with that roomId and construct the correct kind of room on the server.
Separating these two steps means that in the future they can happen on different servers without too much trouble. But that's a future step!
Database migrations for tests
The general development database has migrations applied manually, and they stay indefinitely, or at least till I make a goof and need to wipe the whole thing and start over. But the testing database is reused between apps and is much more volatile. So we need to be able to wipe and apply migrations automatically at the start of unit tests so the expected tables are available.
There was not too much too it, migrations are already isolated into a callable function (as wen we start doing server deployments, we need to also apply migrations there). But there was some other setup that I was avoiding that I was forced to do.
One was setting up nicer config files and loading them to get the database connection details. And the other was making sure the static data for the ORM was being correctly initialized.
Scroll + Selectables
I've been working on how the input will work with longer screens like documents. I've got a bit of a setup now where elements can be flagged as selectable, like buttons. And pressing a direction moves to the next logical one. But also if there is a lot of space in between it will scroll instead.
Here you can see the blue "links" being selected as i press up and down, and the whole screen scrolling until they move into selectable range.
Validate virtual/override
We support virtual and override in NLL. And these translate directly over in C#, and are just both virtual in C++. C# will let you know if you don't override a virtual when you should or other such things, but C++ is more lax and will let pretty much anything through.
So I've setup some validation in the transpiler to make sure you must override if necessary. And to check that the base class also has the function marked as virtual.
I was tossing up the idea of just decorating everything with virtual and having the transpiler work out what is override when outputting C#, but for now I think being intentional feels slightly better.
Kanboard direct query PostgreSQL
Now that Kanboard has been moved to PostgresSQL, we can directly query it with nll-Database from our server. This turns out to be much faster than using the inbuilt API, mainly because default API routes don't return quite enough data for me. So I need to make an extra API request per task just to show a listing.
There is also some HTTP overhead which might make database access faster, but the main issue is all the n+1 queries.
Getting access was simple if not a bit unwieldy writing SELECT statements for everything, so I quickly switched over to generating nll-ORM classes to simplify access. These are actually a bit of a hack, as normally the class generator is pretty strict about the structure I will allow, so i manually created them for Kanboard. Most of the logic is within the base classes we inherit from.
I'll keep API access around for doing any mutations, to make sure triggers and everything continue to work correctly. But any reading can now use the speedy direct access.
nll-ORM
In addition to nll-Database, i've created an ORM library to simplify general database access. It has base Row and RowContainer classes for working with rows individually or in bulk.
There is an additional CLI app that scans the current database layout and generates access classes for each table, that inherit from Row and RowContainer.
Using these makes general CRUD operations a lot easier than writing SQL for every little interaction with the database.
Database improvements
There's been several improvements to the database access library for my custom language.
It now supports storing raw binary data, using Blob on the code side and BYTEA on the PostgreSQL side. This meant I needed to update how it was communicating with the database as I was lazy initially and used a text protocol. Using a binary protocol is more efficient now, and particularly with the new columns as there's no conversion of big blocks of binary data to text.
I've also setup some tests and automated running them in Jenkins CI.
Fix return use after free
In my custom programming language, there is the concept of "owned" pointers, that will auto delete themselves when they go out of scope. The problem is that happens just before any return statement. So if that return statement uses the owned pointer, it accesses deleted memory and crashes confusingly a short time later.
I thought this was going to be a pretty painful problem to resolve, but it turned out pretty easy in the end. Now when we inject cleanup, if the last statement is a return we delegate cleanup to it, so it can inject a temporary variable with the result of the expression, delete, then return the temporary variable.
For the rest of the code we just continue as normal, injecting at the end of scope, or before any continue or break statement.
As an example, here was the last straw for me, in nll code we use a locally owned pQuery to get the result.
return pQuery.Execute(pConn) && LoadFromExecutedQuery(pQuery);
In C++ this became:
if (pQuery) delete pQuery;
return pQuery->Execute(pConn) && LoadFromExecutedQuery(pQuery);Which is obviously problematic.
And now the corrected code is:
bool __nll_return_temp = pQuery->Execute(pConn) && LoadFromExecutedQuery(pQuery);
if (pQuery) delete pQuery;
return __nll_return_temp;Fix for defaulting all function params
In my custom programming language, I've fixed the parameter checks around calling functions with all default parameters. Previously it was throwing a warning of no parameter was supplied, even if every parameter was defaultable.
Label wrapping
I've improved the word wrap on labels in CliffyPDA, so now it can render multiline text for cards in the kanboard app.
Labels were previously single line, and generated as a 1bit bitmap. The initial problem with rendering multiple lines is that bitmap gets too big for an ESP32, even at 1bit per pixel. So generating the bitmap for tasks with a lot of text would crash the device.
So the next step was to process the string and break it up into substrings, pre wrapped for each line of the output. This still creates all the bitmap data up front, but there's a lot less empty space so it takes less memory.
This is actually good enough for now, but the next step is that we can create and throw out the bitmap based on if the line of text is on screen or not. And that will make things much more efficient.
Even beyond that we can look at streaming the data in from the server or off disk, and really limiting what we need to keep in memory. But that's pretty extreme so I don't think we'll need to go that far...
Kanboard PostgreSQL
I've converted Kanboard to use PostgreSQL for storage instead of SQLite.
This is so it's easier to access data for CliffyPDA. Currently I'm using the Kanboard API, but it takes many requests to get enough data to build a new frontend. There is support for batching requests, but it was still too slow for my liking.
It was surprisingly not as straightforward as exporting from one to the other as each backend (SQLite, MySQL, PostgreSQL) has separate SQL to create them in Kanboard and there's a slight divergence there. Eg: The user table has an extra is_admin field in SQLite that's not in PostgreSQL. Also PostgreSQL stores the database structure version in a table and SQLite stores it elsewhere.
Also fields can be different types, eg: SQLite does not have a boolean field, so it's just stored as a 0/1 there instead of false/true.
So to convert over, I setup an empty Kanboard instance in PostgreSQL, then truncated each table (except the schema_version) and copied in the data from SQLite. Converting and skipping fields where necessary.
Use shared build and test scripts
Up until now, every new app has been setup with a copy of the scripts to build, test and run. Which has some obvious downsides when they fall out of sync and lose functionality. Also there were separate scripts for C++ and C# which leads to more files to copy and paste.
So now I've got a centralized set of scripts, and simple wrappers for each app. I've taken this opportunity to merge C++ and C# functionality so I can call Build.sh for C++ and Build.sh --CS for C#.
I've also added some bonus functionality to allow easy switching between the default of running C++ apps in gdb to using Valgrind for leak tracking. Previously this would require manually changing the script to uncomment lines.
Older devlogs